When we interact with an AI model, we usually think in terms of words or sentences, but the model actually processes text with tokens. A token is a small piece of text. Sometimes a whole word, sometimes just part of one.
The length of any message, document, or conversation is measured in tokens, not words, which means that the way text is written affects how much the model can process at once. You can take a look at Tiktokenizer and test it in the playground.
Tokens matter because every model has a limit on how many of them it can keep in mind at one time. This limit is known as the context window, and it defines how much of the conversation or text the AI can remember and reference.
If a message exceeds that limit, older information gets pushed out or must be summarized. So, understanding tokens helps explain why some models lose track of earlier details and why larger context windows allow for deeper, more coherent interactions.
Optimizing how you use context windows and manage tokens is one of the key strategies for successful and efficient interaction with LLMs.
Comparing formats by token cost
Let’s do a test.
I’ll use Tiktoken with the o200k_base codification model (the tokenizer for GPT-4o) to count tokens for an array containing a library of websites and a title for each of the sites.
import { Tiktoken } from 'js-tiktoken/lite';
import o200k_base from 'js-tiktoken/ranks/o200k_base';
const tokenizer = new Tiktoken(o200k_base);
const tokenize = (text: string) => {
return tokenizer.encode(text);
};The data we will use will be a simple array of objects:
const DATA = [
{ url: "https://mnadalc.com", title: "Mike's portfolio" },
{ url: "https://hvalls.dev/", title: "Hector's portfolio" },
{ url: "https://facebook.com", title: "Facebook" },
{ url: "https://twitter.com/", title: "Twitter" },
];And also, let’s tokenize different output types:
- XML
DATA
.map(
(item) =>`<item url="${item.url}" title="${item.title}"></item>`)
.join('\n');- Markdown
DATA
.map((item) => `- [${item.title}](${item.url})`,)
.join('\n');- JSON
JSON.stringify(DATA, null, 2);- JSON (inline)
JSON.stringify(DATA);- TOON (Token-Oriented Object Notation)
import { encode } from '@byjohann/toon';
encode(DATA);- As a custom parsed table, following Matt’s Pocock advice We will prepend the column names before concatenating the data
`url|title\n`
.concat(DATA.map((item) => `${item.url}|${item.title}`)
.join('\n'),
);we get the following output:
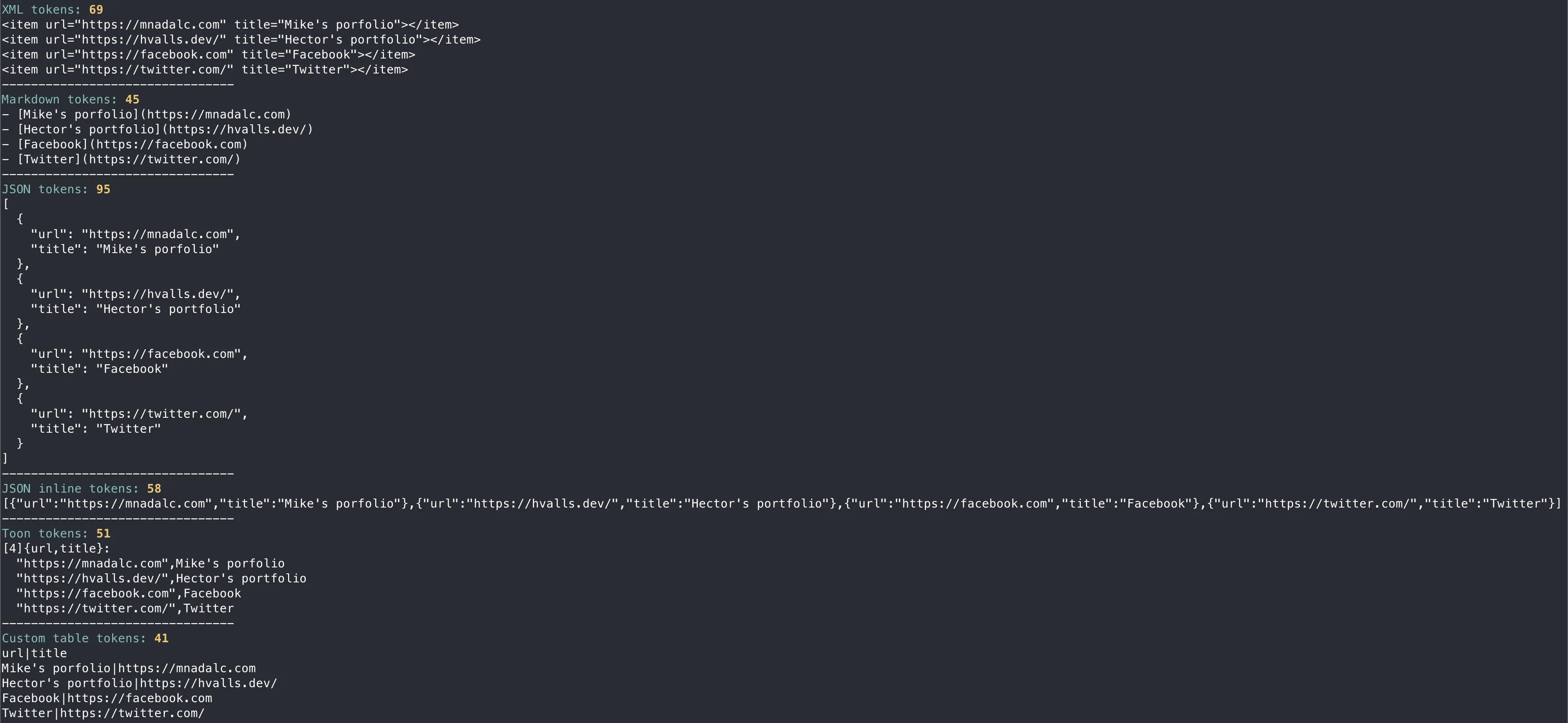
- XML tokens: 69
- Markdown tokens: 45
- JSON tokens: 95
- JSON inline tokens: 58
- Toon tokens: 51
- Custom table tokens: 41
Choosing the right format
As with many things in LLM workflows, the best format depends on your data and goals.
- It’s expected that “pretty” printed JSON uses more tokens than inline JSON due to whitespace and punctuation.
- Markdown lists and compact custom tables are typically token efficient and also human readable.
- XML introduces additional tag overhead, so it typically uses more tokens per item.
- Choosing between TOON or custom tables depends on what you are working on. Creating a custom data table would work for simple and straightforward data. However TOON allows you to use arrays and objects in a simple way, making it a simple and token efficient tool for large structured data.